Blog
Vissza a cikkekhez
Miért nem tud (jól) az AI magyarul?
A ChatGTP-hez hasonló, nagy nyelvi modelleken alapuló AI megoldások elképesztően jók abban, hogy megértsék a nekik címzett kérdéseket vagy kéréseket, és megfelelő választ adjanak rájuk. Legalábbis angolul. De miért látunk gyakran sokkal gyengébb eredményeket, ha magyar nyelvű tartalmat szeretnénk előállítani? Nézzük!
Az amerikai Vox április közepi videója pont azt a kérdést tette fel, hogy amikor bármilyen nyelvet megtanulhatna egy AI, vajon megfelelően elsajátítja-e mindegyiket? Az elmúlt hetekben-hónapokban mi a Crane-nél is rengeteget foglalkoztunk az AI hírekkel, és egy egész sorozatban is összefoglaltuk, hogy mit látunk a marketinges alkalmazhatóságával kapcsolatban. De ezeket az eszközöket próbálgatva nagyon gyorsan belefutottunk abba, hogy kis piacként, a világ egyik legnehezebben tanulható nyelvével ritkán kapunk vissza olyan szöveget vagy fordítást, ami, ha nem is teljesen használhatatlan, nem igényel komolyabb utómunkát egy szövegírótól. Mi áll ennek a hátterében? Phil Edwards, a Vox senior video producere a Common Crawlhoz vezette vissza a problémát.
Mi az a Common Crawl és miért érdekes nekünk? A Common Crawl Alapítvány egy kaliforniai székhelyű nonprofit szervezet, ők viszik azt a hatalmas webarchiváló projektet, ami 2008 óta ingyenesen letölthető és kutatható adathalmazokat szolgáltat bárkinek, aki kutatási, oktatási vagy akár üzleti célra használni akarja azt. Saját fejlesztésű crawler botjuk évente többször végigjárja a teljes nyilvános webet, és mindent indexel. És kihasználja – többek között – a Common Crawlt a legnagyobb forrásaként? Az OpenAI, ChatGPT és DALL-E-fejlesztője.
Arról, hogy milyen adatforrásokból tanult a jelenlegi modell, a GPT-4, nincs nyilvános adat, és a GPT-3 forrásait se veri nagy dobra az OpenAI, de ebben a tudományos publikációban megtaláljuk a választ.
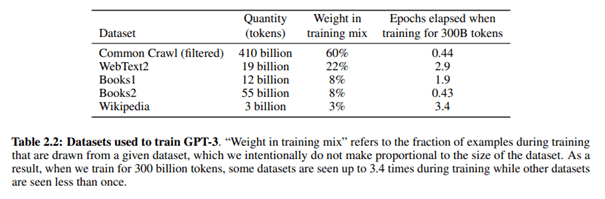
Ebben a tréning mixben a Common Crawl adta az adatok 60%-át – azon belül is egy 2016 és 2019. közötti, eredetileg 45 terabájtnyi adag, ami aztán tovább szűrtek egy mindössze 570 gigás csomagra. A WebText 2 olyan weboldalak szövege, amiket legalább 3 upvote-tal rendelkező Reddit posztban linkelt valaki, de ez már sokkal kevesebbet nyom a latba, csak 22%-ot. A további források pedig még kevésbé jelentősek súlyban, de a két online elérhető könyvkorpusz van még az adatszettben, és utolsó helyen a Wikipedia is befigyel (azon belül is az angol nyelvű oldalak).
A GPT-2 és a GPT-3 alapvetően ugyanakkora adatszetten tanult, csak a 2 még „csak” 1,5 milliárd paraméterrel dolgozott, míg a 3 már 175 milliárddal, így komplexebb mintázatokat is fel tudott ismerni az adatok között és magában a nyelvhasználatban is. Ezáltal pedig a modell az emberek adta inputot is jobban megérti és a válaszai is jobban hasonlítanak egy emberi válaszra. A nagy nyelvi modellek tehát arrafelé haladnak, hogy a több adat nem feltétlenül jobb, amíg az adatszett jó minőségű és nagyobb, több paraméterrel dolgozó modellt engednek rá. De mi a helyzet, ha az adatszett döntő többségben egyetlen nyelvből építkezik?
Ez itt az utolsó elemzett Common Crawlban (2023. március-április) indexelt HMTL oldalak nyelveinél az első 25 helyezett.
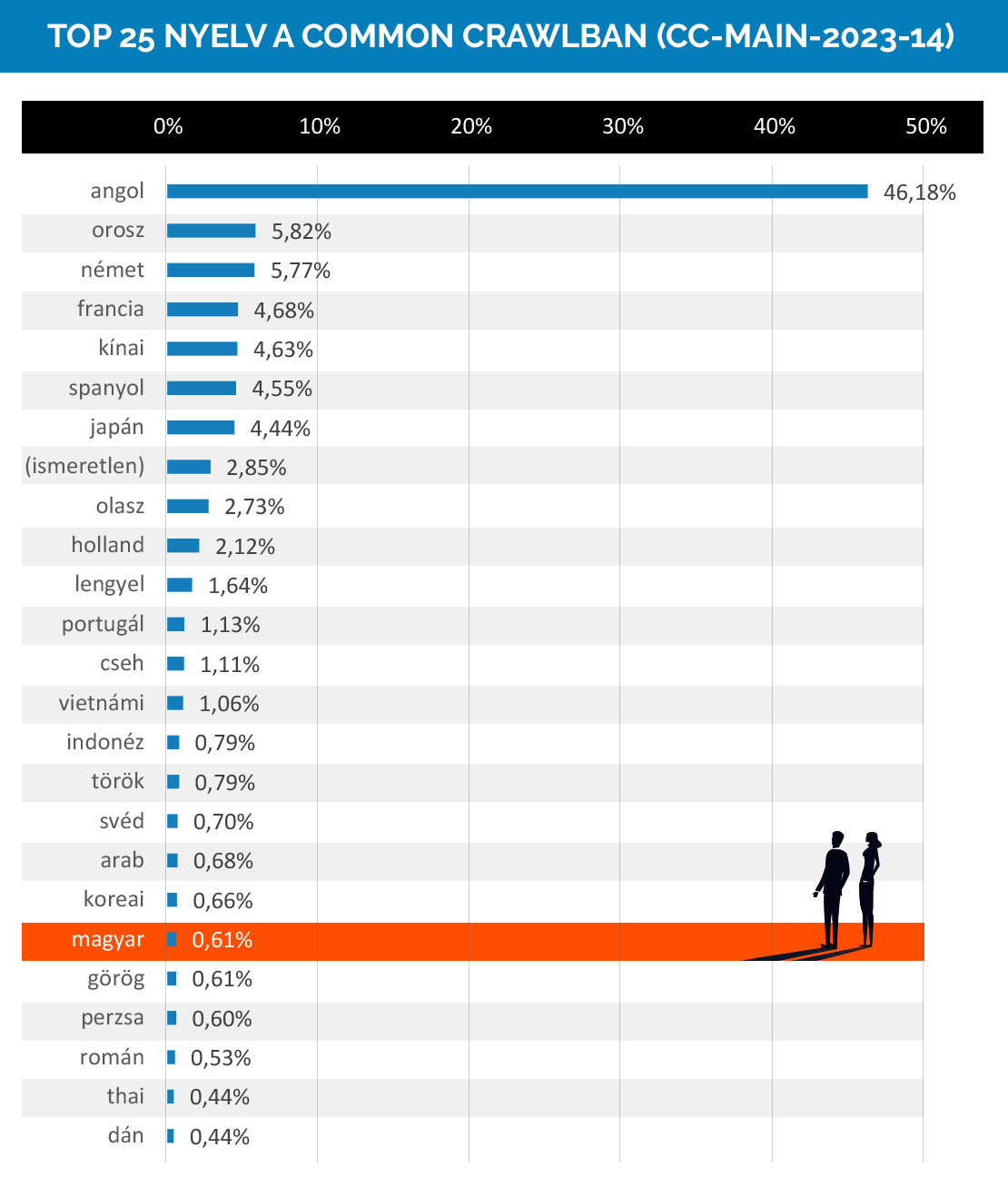
Az angol toronymagasan vezet, a vizsgált oldalak majdnem fele angol nyelvű volt, még ha tavaly november-decemberi crawl óta március-áprilisra 0,13%-ot csökkent is az angol oldalak súlya. A magyar nyelv a listán a 20., ami ahhoz képest, hogy a lakosság mérete alapján a világon a 94., területre 110., a legtöbbek által beszélt nyelvek alapján pedig 92. helyen vagyunk, meglepően komoly súlyt ad nekünk; de az összes vizsgált lapnak ez így is csak a 0,61%-a.
De végül is a Common Crawl „csak” 60% volt, a teljes adatszettet vizsgálva csak kiegyensúlyozottabb a helyzet, nem? Hát, nem éppen. Az OpenAI saját GitHub GTP-3 archívumának elemzése alapján így áll a modell az adatszettben használt szavak nyelve alapján:
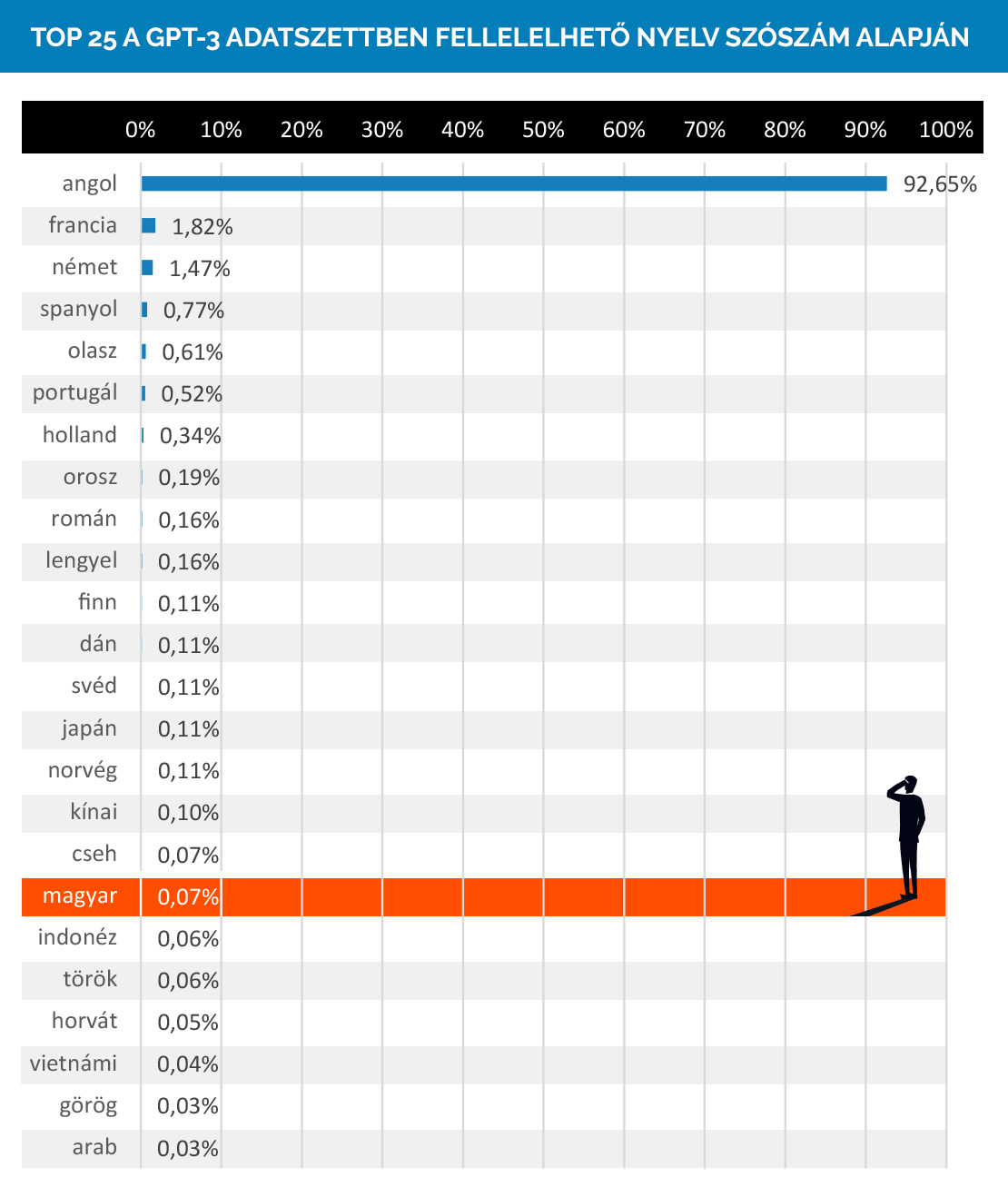
Majdnem 93% angol, 0,065% magyar… És igen, lehet, hogy nem csak az adatmennyiség számít, nagyon fontosak azok a paraméterek. Elvégre a magyar szövegek, amit mondjuk egy ChatGPT-től látunk, nem boraszatóak, csak nem is élnek meg egy szövegíró nélkül. Ez a 127 millió magyar szó láthatóan kevés a modellnek ahhoz, hogy igazán elsajátíthassa a nyelvet.
Ennél is szomorúbb adat, hogy globálisan körülbelül 7000 (!) nyelvet beszélünk, és ebből mindössze 20 adja a természetes nyelvek feldolgozásával (Natural Language Processing, vagy NLP) foglalkozó kutatások döntő többségének fókuszát. Érdemes megnézni a Vox videót, ahol három kutatóval is beszélgetnek, akik olyan új adatszetteket próbálnak létrehozni, amik választ jelenthetnek erre a problémára olyan elhanyagolt, kevés forrással nyelvek rendelkező esetében, mint a jamaicai kreol vagy a katalán. Vagy épp egy üresben álló francia szuperszámítógéppel egy open source, 46 természetes nyelvet (köztük sok hagyományosan kisebb digitális lábnyommal bíró afrikai nyelvet) és 13 programozási nyelvet tartalmazó nagy nyelvi modellt alkotnak, mint a Bloom.
A magyar nincs köztük, de akkor mire számíthatunk itthon? Megbízható nyelvmodellt készíteni Magyarországon nem kis falat, és az, hogy jelenleg nincs ilyenünk, elsősorban nem a szándék, hanem az anyagi keret és a modell betanításához szükséges korpusz hiányára vezethető vissza. Jó hír azonban, hogy a GPT-k fejlesztéséhez felhasznált nyelvi korpuszhoz hasonló, bár annál jóval kisebb szöveggyűjtemény összeállításán dolgozik az ELTE Digitális Bölcsészet Tanszékének és a Digitális Örökség Nemzeti Laboratórium (DH-Lab) közös kutatócsoportja. A fejlesztők április végén adtak interjút a Qubitnek, ahol mesélnek a külső finanszírozás szerepéről, hogy mekkorát kell küzdeni minden digitálisan fellelhető jó minőségű forrásért a szépirodalmi művektől a szakdolgozatokig, vagy éppen hogy mi fán terem egy digitális bölcsész. A konkrét betanítási folyamat, maga a modellépítés idén nyáron kezdődhet, de a stabil és megbízható viselkedéséhez elengedhetetlen lesz majd a finomhangolás is. Még arra is van módszerük, amikor a modell következetesen ront, elfogadhatatlan (például rasszista) megnyilvánulásokkal válaszol. Mi lesz az eredmény? Mi biztosan kíváncsian várjuk!